One of the most important aspects of using DigitalOcean is accessing it via smartphones and tablets. Using the applications or even terminal to check the status of the server is extremely important. I am a member of the Apple ecosystem hence my primary concern is the iOS apps. In this post, I would like to share my experience with different apps that give the control of your servers in the DigitalOcean cloud. I ordered the apps simply by their names.
But in short: Droopls is the best but comes with a price. Prefer Manager for DigitalOcean. It is mostly same as Droopls but free.
Compass for DigitalOcean
This iPhone app permits you to control your servers. The login process uses OAuth2 API of DigitalOcean. You can add more than one account. That is an important feature differentiating this app. For logins, your API key, if it exists, cannot be used. Only your user name, password and two factor authentication is applicable. Under your accounts, you will see your servers which belong to that specific account and their status.
You can also power on/off or reboot them. There exists a “Droplet History” option but in iOS 10.0.2, it constantly crashes.
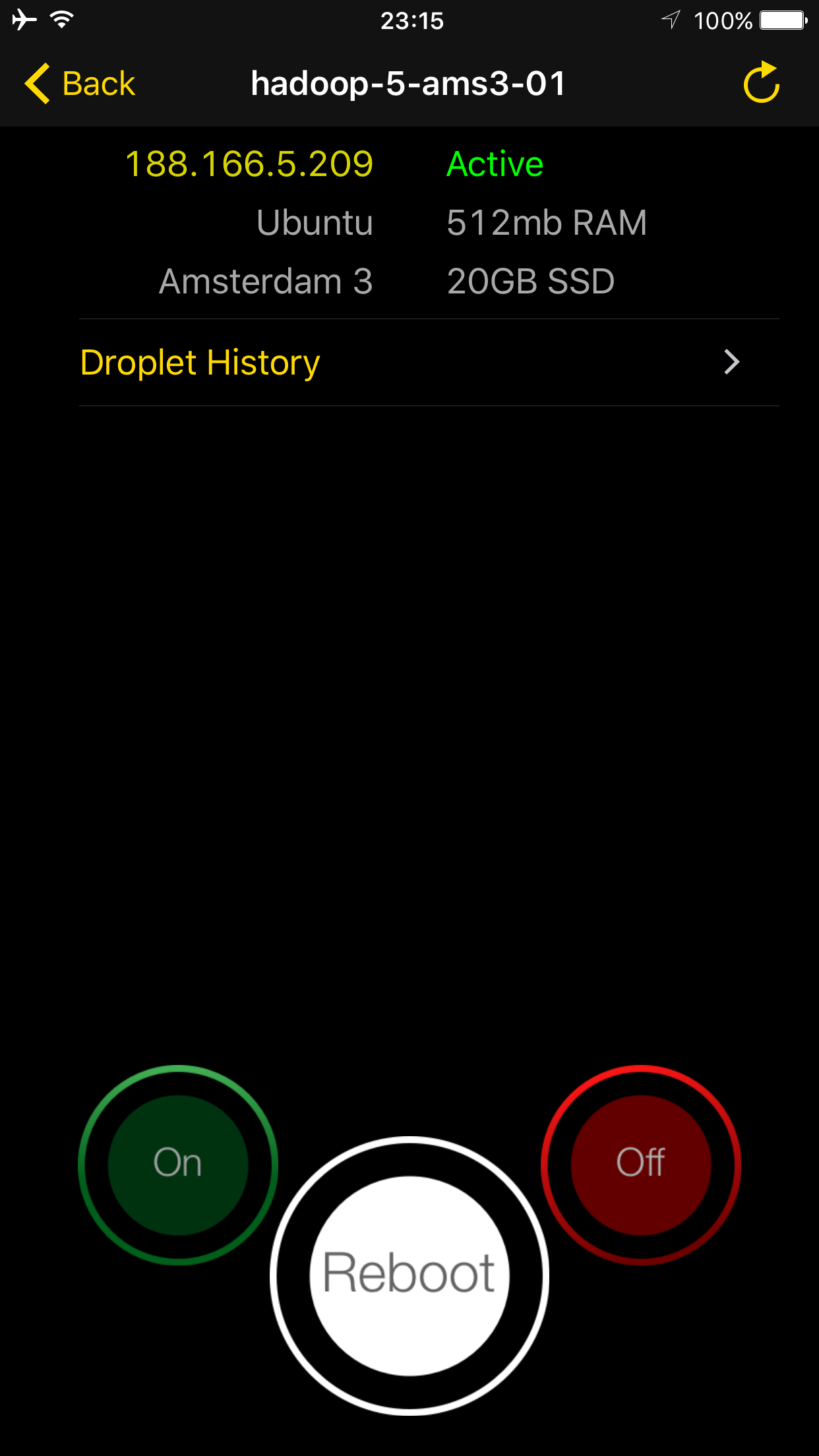
Unfortunately, you cannot add new droplets or delete / modify them. These two factors can be deal breakers for many users.

Its last update is done on May 5, 2015 and it costs $0.99. It offers no in app purchases.
DigitalOcean Toolbox
It is a universal app however, for some reason, in iOS 10.0.2, menu items do not appear on iPad.

It supports split view and it also has an Apple Watch app. It uses only the OAuth2 API for logins. It does not support multiple accounts. You can only use one account at a specific time. The droplets are represented by small rectangles.
Inside, you can get necessary information about it. Moreover, when you press over a droplet and wait for a few seconds, 5 menu items appear as a quarter of a circle. They are power off, power cycle, take snapshot, disable backup and destroy. Every action selection presents a confirmation dialogue. That’s how I learnt all of them.
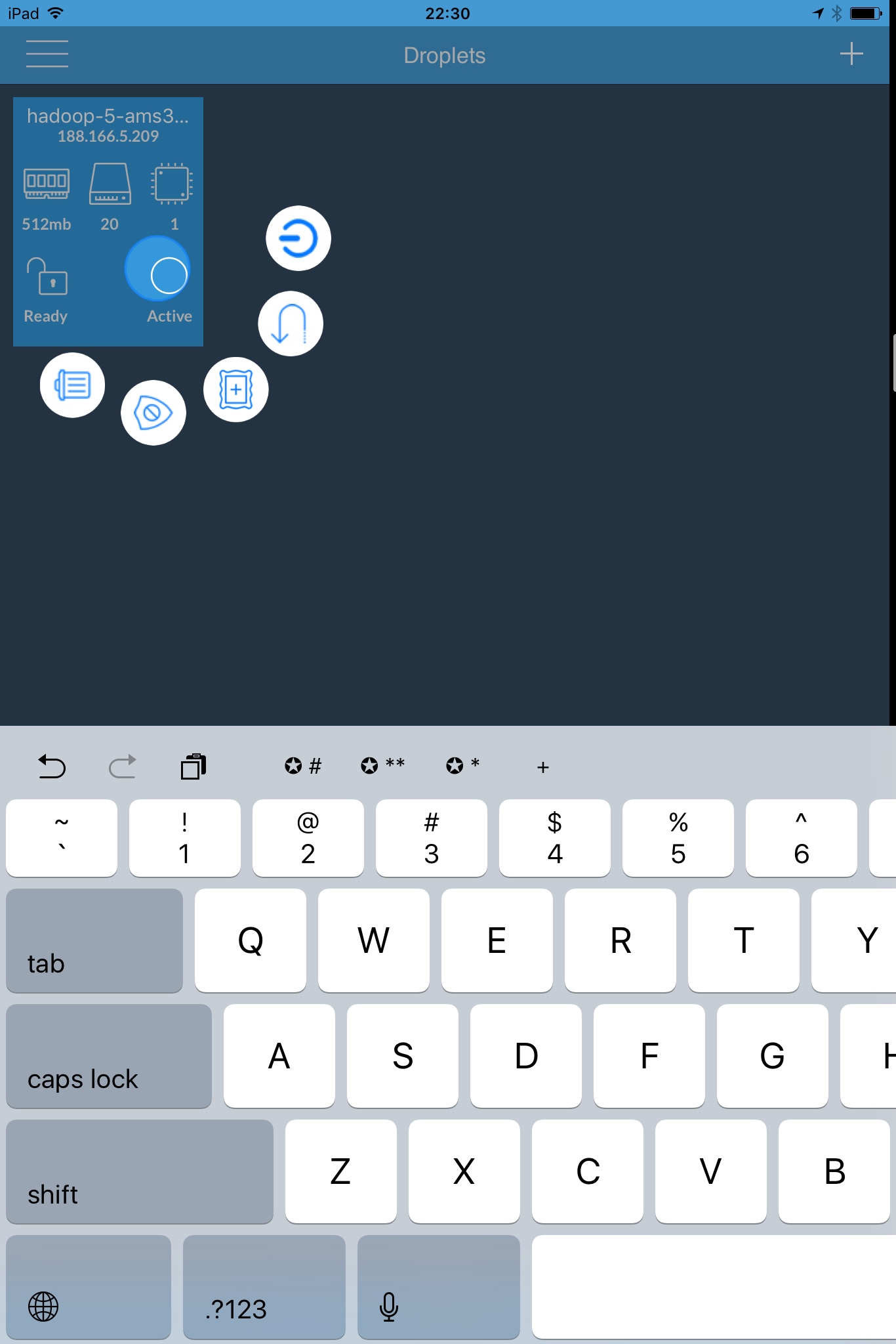
Since the touch point is the center, try to press to the right side of the droplets which appear on the left of the screen and press to the left side of the droplets which appear on the right of the screen. The actions are small circles and their functions are closely related to the icons but to activate them, you need to swipe your finger towards the action circle button. Unfortunately, the images of the actions are not appropriate for landscape orientation of iPad. It seems that a hard to use design choice was implemented.

Other than the droplet actions, you can also see the images. The images contain both the distribution images and your snapshots / backups. An interesting point is that, only a portion of distributed images is displayed. For example, we can merely see 3 distributions of Ubuntu, although there are more of them.
Also, while adding a droplet, we cannot choose every payment option. Only most affordable three option is available. Furthermore, we cannot create a droplet using our snapshots. Only distribution images can be used to create a brand new droplet.

Regarding images, we can transfer, rename or destroy a snapshot. Interestingly, the same set of operations are available for the distribution images. However, when we chose any of them, we get a message stating that these operations are forbidden for those images.

Its last update is done on February 13, 2016 and it costs $1.99. It offers no in app purchases.
DigitalOcean Manager
This is also a universal app but it does not support split view. Contrary to the previous apps, to logon to DigitalOcean Manager, we must provide our API key. There is no way to logon with our user names and passwords. This app does only enables one account at a time. The droplets are presented as a list.

Touching the server row brings the Droplet information and actions menu. Moreover, the whole screen is occupied by a big map. It shows where your server is. To me, this is a waste of real estate. The available droplet actions are Reboot, Power Cycle, Shutdown, Power Off and Power On. You can also take a snapshot of your server in here.

You can add droplets. The interface of droplet addition is quite simple and frankly not very attractive. The distribution images are quite limited and there is no option to create a droplet from your snapshots or backups. There is no way to destroy a droplet in this app.

Its last update is done on May 14, 2015 and it costs $0.99. It offers no in app purchases.
Droopls
The Droopls app is iPhone only but it has by far the best UI. We can login to a single account, with password only. Default view is our droplets.

We can create new droplets. The creation process lists all sizes but the high memory configurations are not easily identifiable.


As images, we can use all distributions, applications and also our snapshots and backups.



While creating the droplet, we can change private networking, IPv6 and automatic backup settings. These operations are also available after droplet creation. We can also generate an SSH key for that droplet.
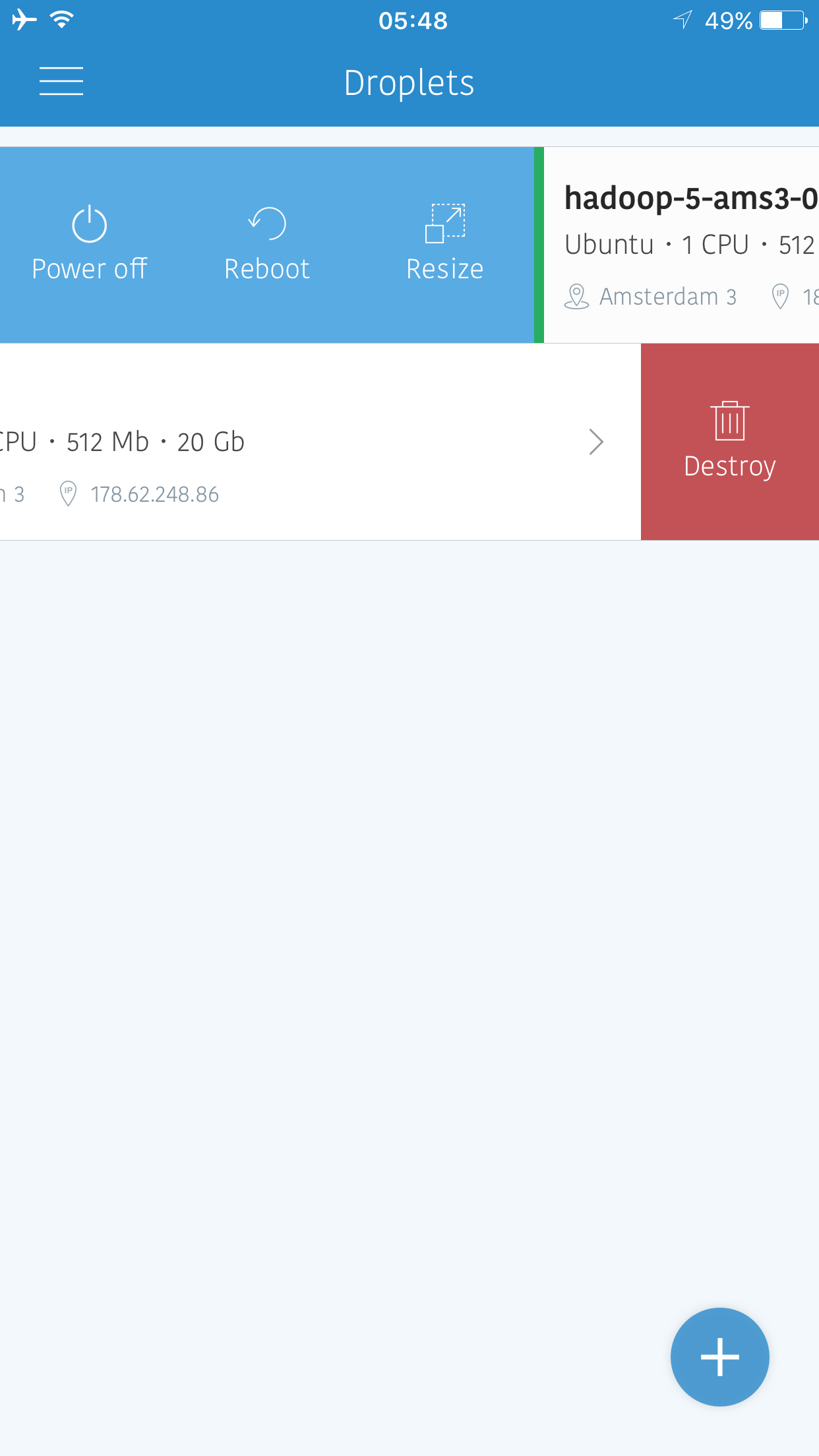
As droplet operations, we can rename, reset password, restore from snapshot, reboot, power off, power cycle and destroy the droplet.

Interestingly, we cannot resize the droplet from settings menu. Rather, we need to get to the list of droplets and make a right swipe to reveal that option.
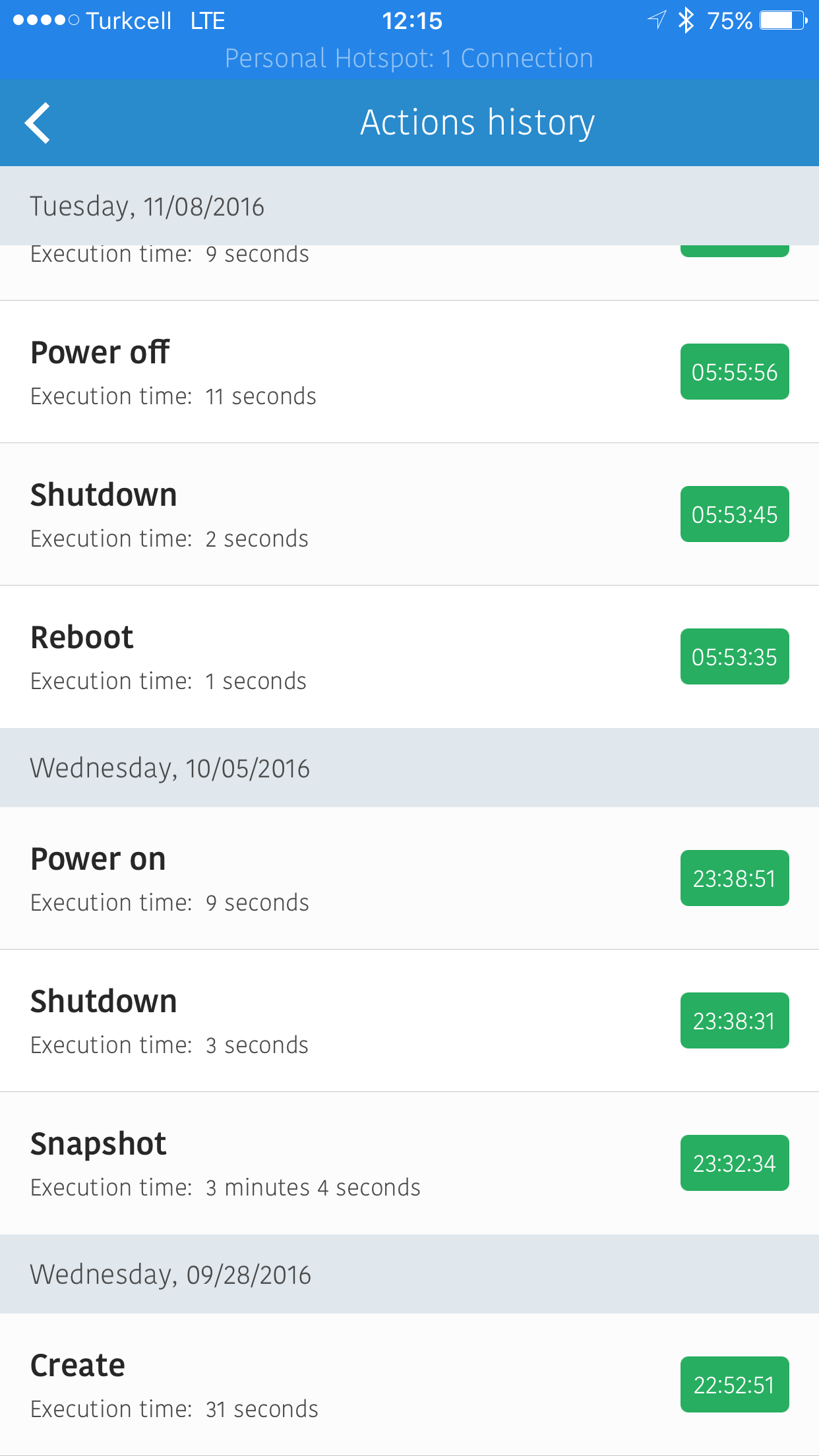
The history of each droplet can be seen in a descending order of time fashion.
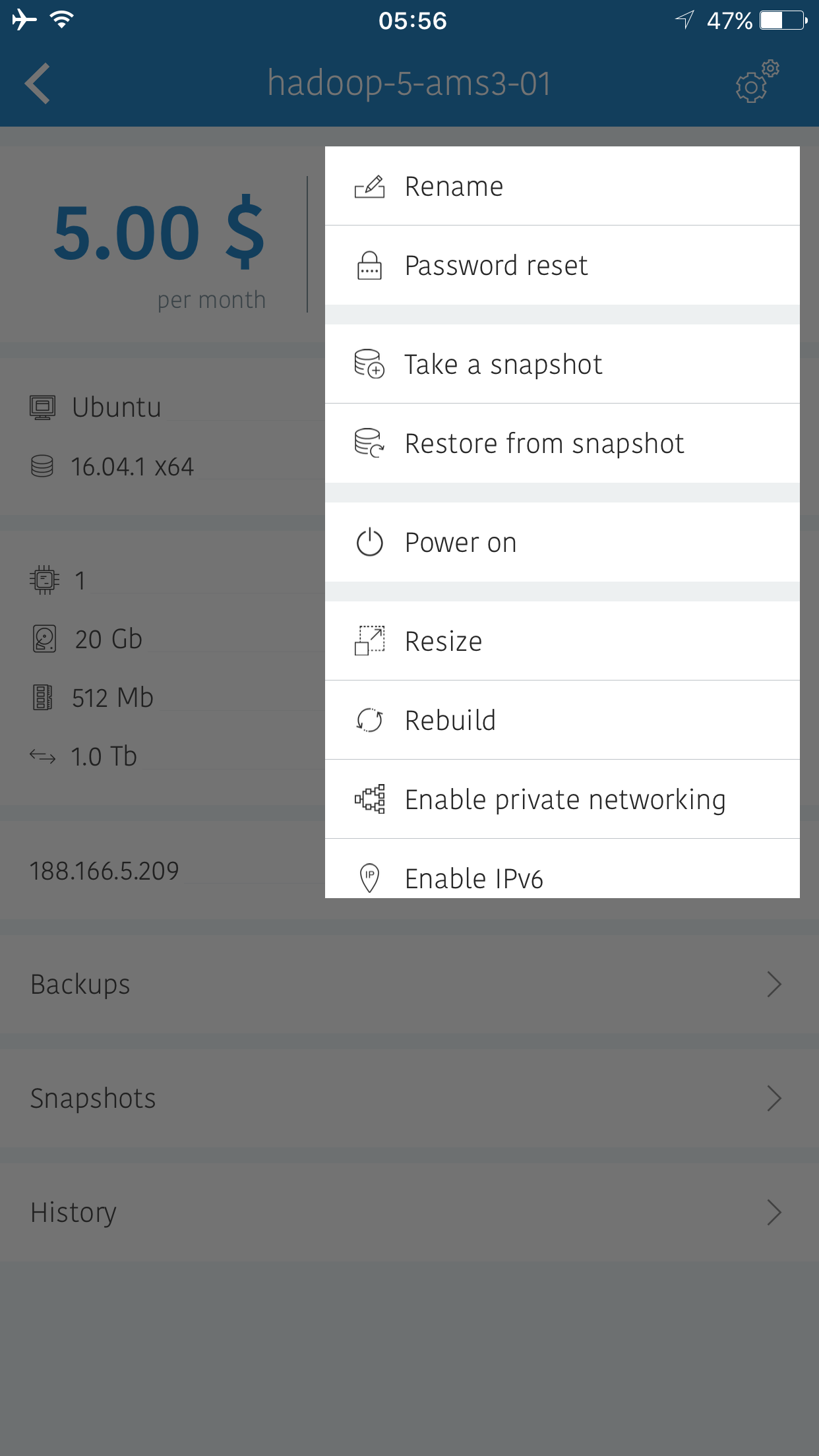
To take a snapshot of a droplet, we first need to shutdown the droplet. The menu is updated after the shutdown. Later, we can take the snapshot.

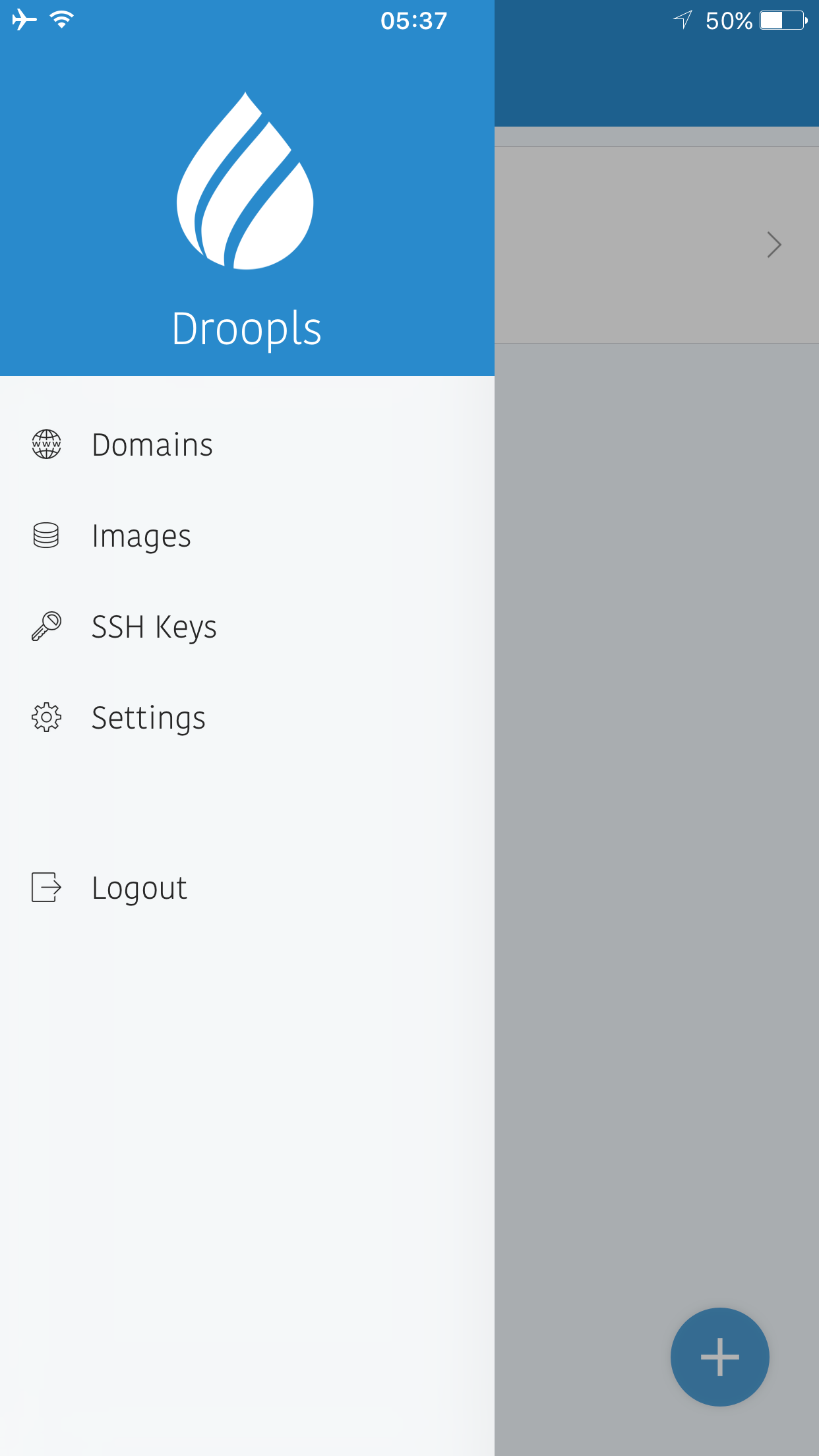
We can create domains and see snapshots. For snapshots, we have the ability to transfer, rename and delete them. As a last set of operations, we can add SSH keys.

It is the most pricey app in the bunch, requiring a one time purchase of $4.99. It has no in app purchase option and updated on December 3, 2015. For the time being, it is “the app” to use for DigitalOcean. Period.
MagicOcean
It writes “Login Button”. Why there is “button”? I do not know. It directly takes you to the login web page of DigitalOcean. Although it is the most recently updated app, It does not work after login! I tested it with 10.1 and 10.1.1
August 22, 2016
Manager for DigitalOcean
This iPhone only app gives us the option both to login with our account or to authenticate with token. We can also add more than one account and select it to see the activities and droplets under it. These can be found in the Settings menu.

The droplet creations, power actions for droplets and account removal can be modified to require confirmation. Deletion of droplets, snapshots and keys always requires confirmation. We can also change the color of the app in the settings menu.

We can see all our droplets and create new ones.

During a new creation, size selection can be a little bit confusing. The tiers are ordered by RAM but it would really be nice if high memory droplet pricing was represented differently from the regular ones.

The information button on the top right shows the CPU, storage and network transfers. There seems to be a problem with loading the rows, since even you tap the info button once more and close the details, some previously unseen rows still show their respective details.
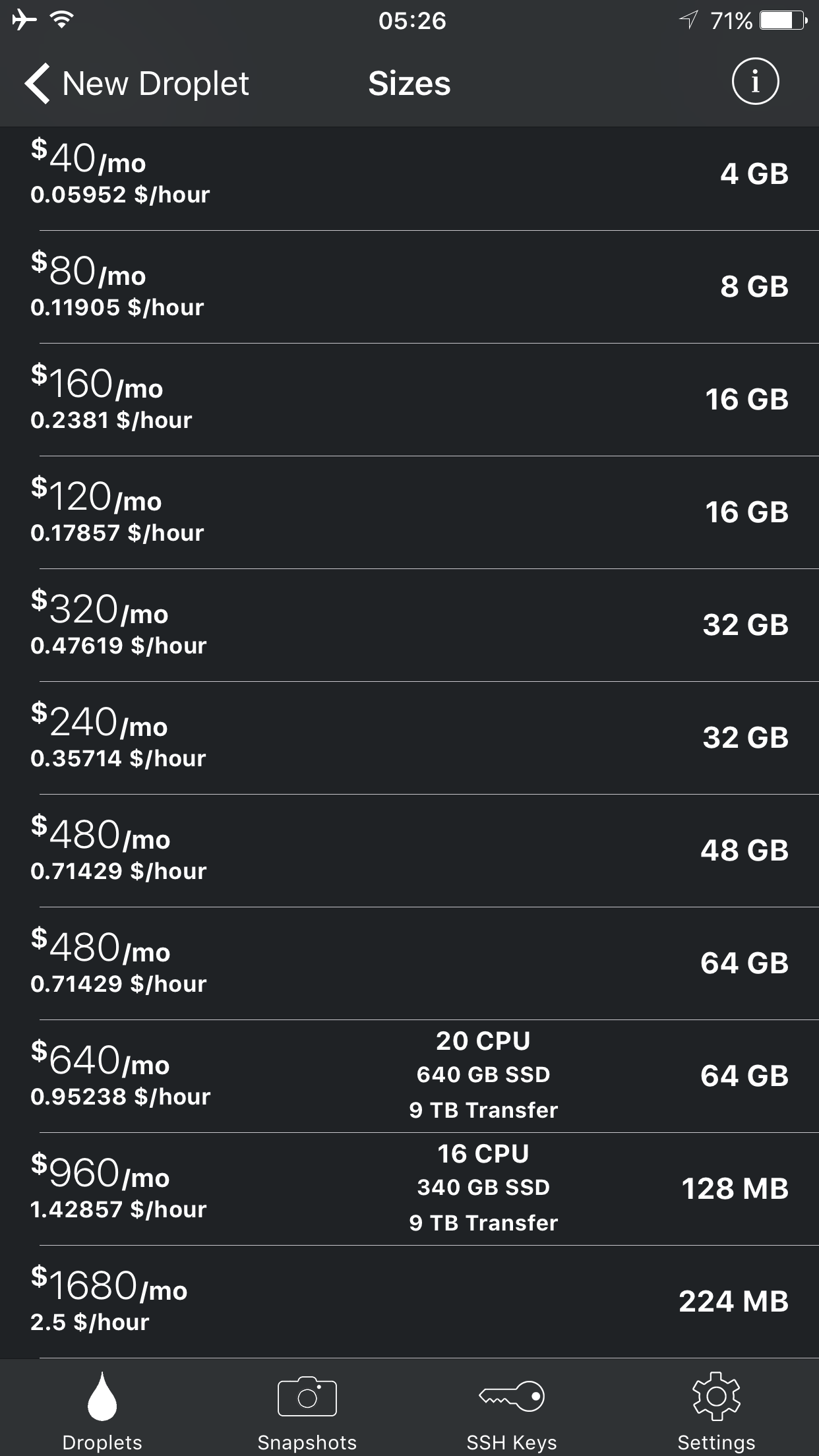
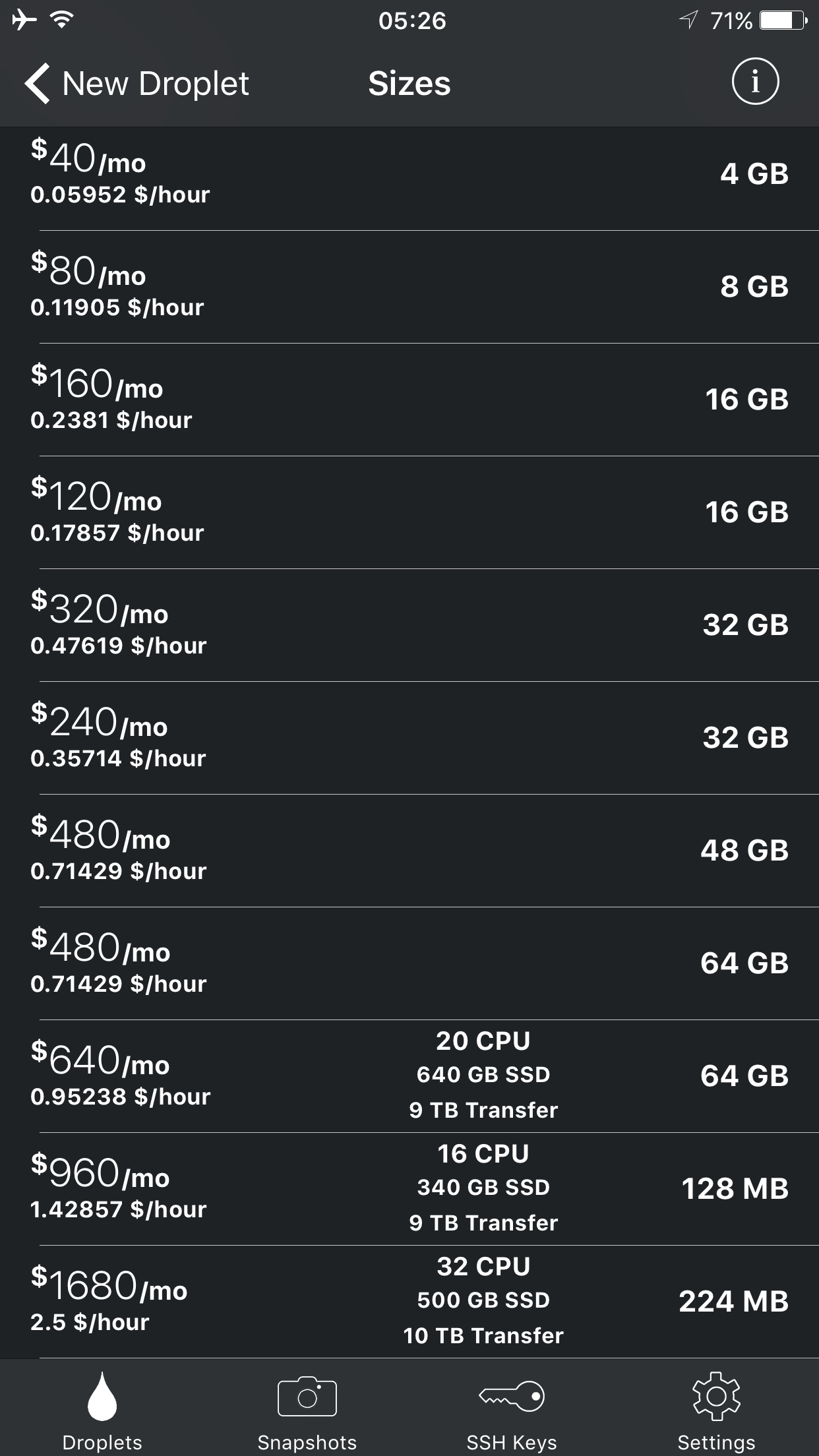
We have the option to choose from distributions, applications and our snapshots as the base image for a new droplet.



Since we can use snapshots, transferring them from one place to another can be crucial. Manager for DigitalOcean has this nice movement feature. We can also generate SSH keys.
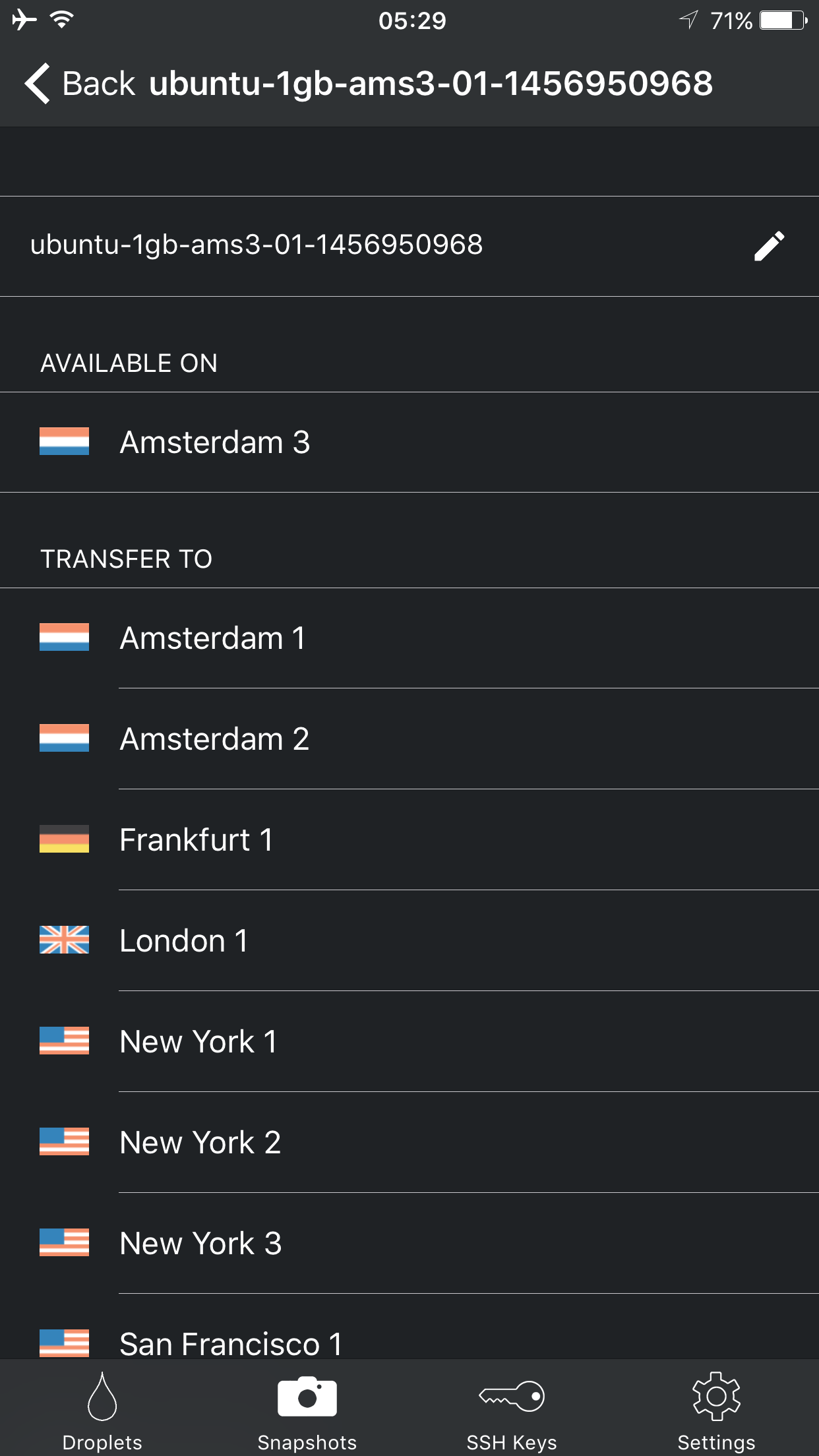
The droplets can be rebooted, shutdown.

We can take the snapshots of them. Even we can rebuild them. Destroying a droplet is also available.

A nice touch was easily copying the network information by a single tap. This is really handy if you use those in other apps such as Prompt 2.

The nice thing with the UI is that, there is no left/right swipes to see the available actions or options. Everything is clearly presented inside each view.
Its first and only deployment came on December 13, 2015. It is free and there is no in app purchases.
Snapper for Digital Ocean
This universal app is free but with ads on the very bottom. To remove them, you need to make an in app purchase of $0.99. Since it has been quite a while from its last update, its visuals are a little bit muddy in iPhone Plus and iPad Pro 12.9 models. It does not support split view. To login, you are directed to the Digital Ocean website. You cannot use API keys to login and multi account usage is impossible.

The main menu permits us to see a list of our droplets, domains and SSH keys. We can add domains, SSH keys but not droplets.The droplet information is quite limited. For example, we cannot get storage information for our droplets.

To go back to the list of droplets, we need to get back to the main menu and then hit the droplets link again. Not user friendly. We have all the options to reboot, shutdown, power on and destroy a droplet. We can also disable backups. Taking a snapshot is not available.
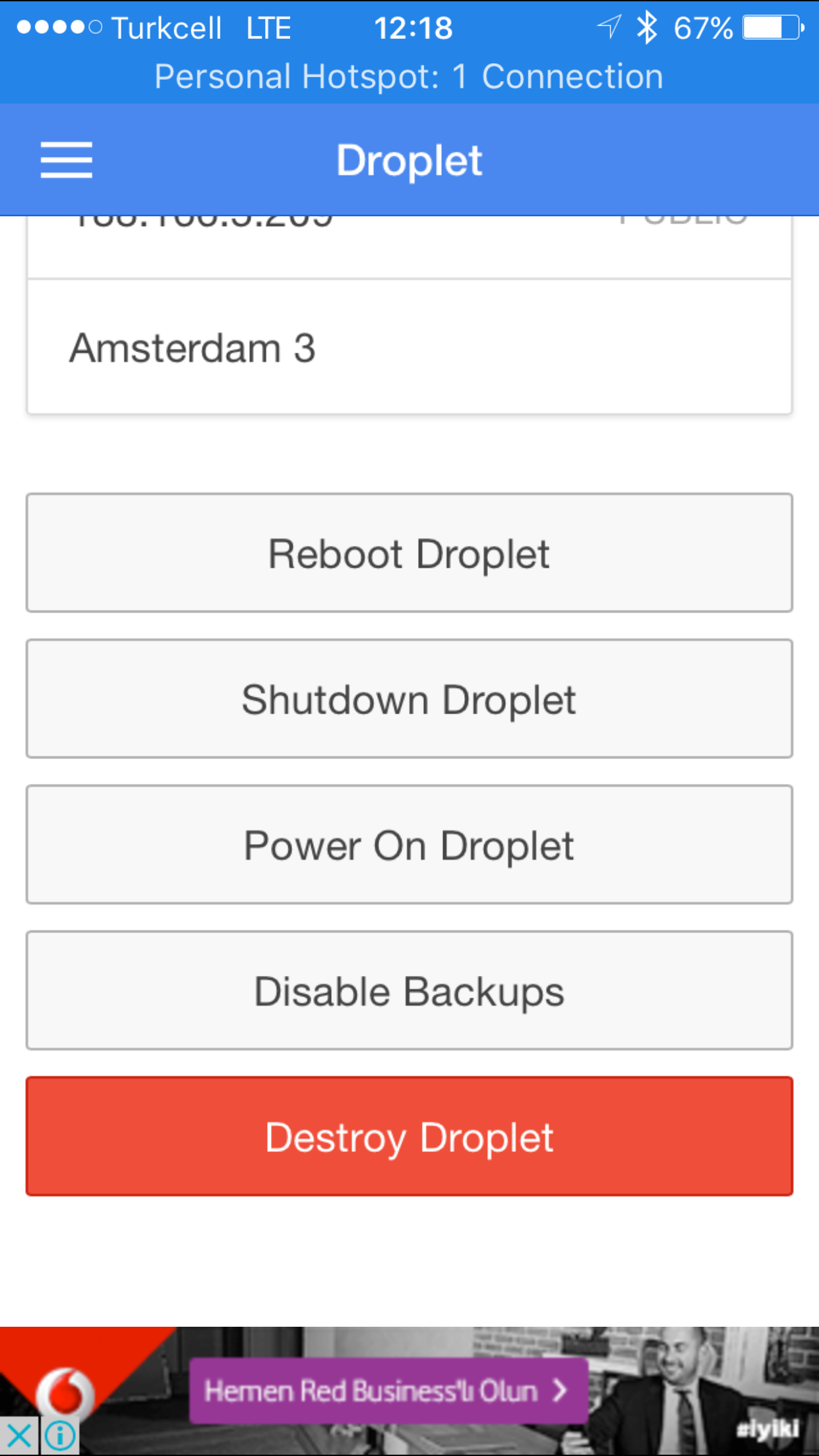
There is a setting called “Droplet Safe Mode”. First, I thought that it disables to destroy droplets but it does not work that way.

Actually, what it does is that, for each droplet action, it requires you to enter 0000 (4 zeroes) to complete the process. For destroying a droplet, it always wants you to enter that, regardless of the status of “Droplet Safe Mode”.

It is last updated on October 8, 2014.



























 And here is the final result:
And here is the final result:
