As a start Hadoop studies, I decided to download a set of small files to play with. By small files, I mean small files with respect to really big ones. My choice is This is My Jam data dump. There are 3 files, jams.tsv, followers.tsv and likes.tsv. They are of size 369, a06 and 394MB respectively.
First, I copied to largest one to the HDFS in node1:
hdfs dfs -copyFromLocal /media/sf_Downloads/This\ is\ my\ jam/likes.tsv /
Since my block size is set to 5MB, there should be more than 70 blocks. I also set the replication factor to 3. So, how can we learn the exact number of blocks and where they are?
hdfs fsck /
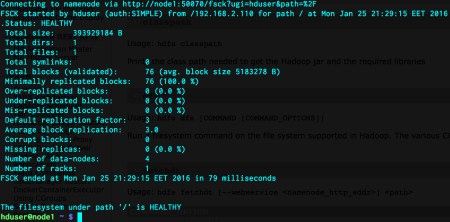
Now, here, we can see that the total size of our single file is 393929184 bytes. When we divide this by 5x1024x1024, we get a little bit more than 75. So, the number of blocks should be 76. That is correct. We also verify that the replication factor is 3. That’s good. The filesystem is also healthy. Let’s dig into more details about the individual blocks.
hdfs fsck / -files -blocks
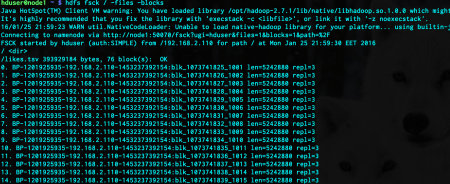
Each block has three information. The second and the third ones are self-explanatory. Let me dissect the first one. This item is composed of three different items, separated by underscores (_). The first item is all the same for each block. This represents the block pool id. It tells us which node generated this block. In our case, this must be the node1. When we format the HDFS, the namenode assigns a unique ID as the block pool ID, and a different ID as cluster ID. These IDs are all the same for the nodes in that cluster. We can check that by investigating the necessary files under node1:
cat /hdfs/tmp/dfs/data/current/VERSION cat /hdfs/tmp/dfs/name/current/VERSION
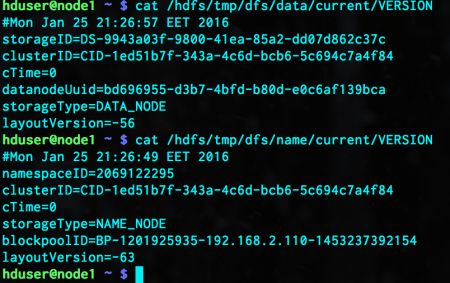
The block pool ID is the same as we saw in the fsck output. The second item in the block information is the unique block ID. The last part is the Generation Stamp. When that block changes, it is incremented accordingly. So, with all these three items, a block can be uniquely identified.
We have 76 blocks and the replication factor is there. We also have 4 active data nodes. The question is, where do these 76×3 blocks reside?
hdfs fsck / -files – blocks -locations
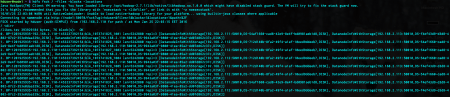
The start of the line is exactly the same as the output of the previous fsck command. The remaining part shows us where that block can be found. It is a list of DatanodeInfoWithStorage objects. The size of it matches our replication factor. That information includes the IP and port of that node, storage ID and storage type. The storage type is mostly DISK but it can also be SSD, ARCHIVE or RAM_DISK.
What about the storage ID? HDFS formatting assigns each node a unique storage ID. Nodes can have multiple disks but this ID is assigned to the node, NOT to the disk of a node. We can examine this, for example, in node2:
cat /hdfs/tmp/dfs/data/current/VERSION
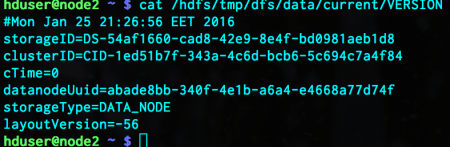
The storage ID matches with the corresponding entries in block location information.
We can also verify the same information from web application of HDFS.
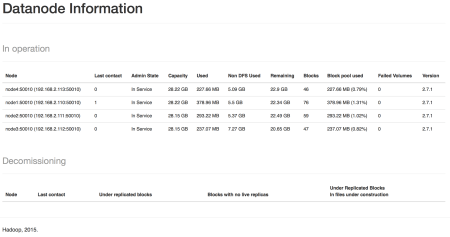
All four datanodes are active and their block counts are also visible. node1 has all the blocks. This is normal but can cause performance problems when we run our tasks in the cluster. We can browse the files:
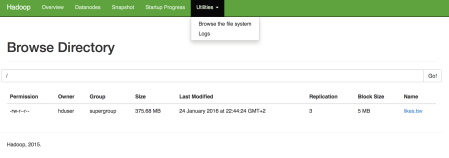
There is only one file. When we click on it, we get the individual block information:
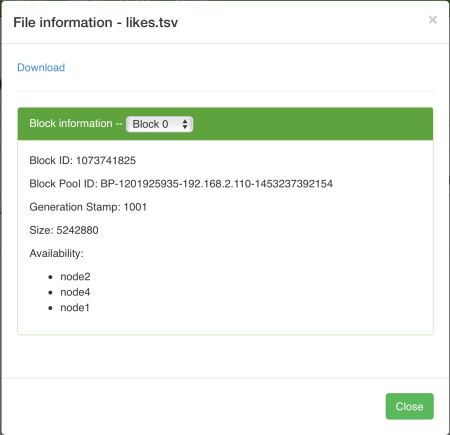
These are exactly the same as the ones we gathered through command line fsck commands. A small detail is that, the name of nodes are presented in Availability section, in place of IPs and ports.
In the next post, we will prepare our development environment.

Leave a comment