The installation of Raspbian Operating System to the second RPi is exactly the same as the first one.
There are a few differences in the Hadoop installation though. The other guides mention only the things that change but I want mine to be as comprehensive as possible. Therefore, I copied and pasted the Hadoop installation to the first RPi, and pay special attention to the changes by making them bold and adding critical information.
Before starting the Hadoop installation, there are a few steps that we need to be sure of. The java version should be 7 or 8.
java -version
will show the installed java run time environment. If, for any reason, we cannot run it, or java 6 or below is displayed, we can get the required version by
sudo apt-get install openjdk-8-jdk
After this, renaming the RPi hostname and assigning a static IP for it will be very helpful. We can create/modify the /etc/hostname file. The name node2 can be a good candidate since we will use a few more RPis.
sudo vi /etc/hostname
The raspi-config menu contains the hostname change mechanism under “Advanced”(9) and “Hostname” (A2).
We can assign a static IP by appending the following to /etc/dhcpcd.conf file.
sudo vi /etc/dhcpcd.conf
interface eth0 static ip_address=192.168.2.111 static routers=192.168.2.1 static domain_name_servers=192.168.2.1
I gave my values here, but please change yours according to your network information. Restarting RPi will be required. If you somehow modify /etc/network/interfaces file, your RPi will have 2 IPs, one is the static you provided, the other is the dynamic. To eliminate the dynamic one, we are to apply the aforementioned solution.
When you want to access either node1 or node2 from your Mac, or from each other, you cannot do that by using their names. But you can do that by using their IPs. What’s happening? The problem here is that, our routers have no clue about node1 and node2 in our local network. So, each machine must map the node names to IPs. There are a few alternatives but I have used the simplest solution. In each of RPis, I opened the file /etc/hosts and appended the IPs and their corresponding names.
sudo vim /etc/hosts
192.168.2.110 node1 192.168.2.111 node2
This way, every RPi will know the others both by name and by IP.
Next step is preparing the Hadoop user, group and ssh. The three commands below create hadoop group, add the hduser to that group and enable the hduser to do super user operations.
sudo addgroup hadoop sudo adduser --ingroup hadoop hduser sudo adduser hduser sudo
The last command will trigger a set of options. First, we need to form a password for the hduser. I left the other options blank. Now it is time to login with our new hduser. From now on, we will be working as it.
Since ssh is the main medium of coordination, the hadoop users must ssh to other nodes and their localhost without a password.
ssh-keygen -t rsa -P ""
I left the file location as is. We need to copy that file (~/.ssh/id_rsa.pub) as ~/.ssh/authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Let’s check if we can ssh localhost.
ssh localhost
We are asked to add localhost as a known host. That’s ok. In our second login with hduser, there shouldn’t be any questions to be asked. Even a password is not required. That’s what we wanted to achieve.
The node1 will be our master RPi. Therefore, it needs to login to other RPis in the cluster. For that reason, we need to add the authorization key of hduser@node1 to the authorization keys of other RPis.
hduser@node1 ~ $ cat .ssh/authorized_keys
Copy the content over to
hduser@node2 ~ $ vim .ssh/autorized_keys
This last file will contain only the authorization key of hduser@node1 .
We do not need to download the Hadoop installation files again. We already have that in node1. Get it by using
scp pi@192.168.2.110:/home/pi/hadoop* /
Now since we are ready, we can unzip the hadoop zip file. I preferred to install it under /opt/. You can choose anywhere you like.
sudo tar -xvzf hadoop-2.7.1.tar.gz -C /opt/
The default directory will be named after the version. In my case, it became /opt/hadoop-2.7.1/. You can change anything you like. I am sticking with this one. The owner:group of the newly created folder should be hduser:hadoop
sudo chown -R hduser:hadoop /opt/hadoop-2.7.1/
Now we can login with hduser again. From now on, it will be our only user to work with.
There should be a file named .bashrc in the home directory of hduser. If not, please create it. This file works every time hduser logs in. We will define exports in here to use hadoop commands without specifying the hadoop installation location each time. Append those three exports to .bashrc file.
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::") export HADOOP_INSTALL=/opt/hadoop-2.7.1 export PATH=$PATH:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin
You do not need to logout. Simply run
. ~/.bashrc
To test the setting, we can try to learn the hadoop version we are installing
hadoop version
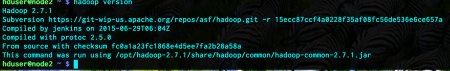
The Hadoop environment information resides in hadoop-env.sh file. We must provide the three parameters. To edit it
sudo vi /opt/hadoop-2.7.1/etc/hadoop/hadoop-env.sh
Search for the following export statements and change them accordingly.
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::") export HADOOP_HEAPSIZE=900 export HADOOP_DATANODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_DATANODE_OPTSi -client"
There is another set of files under the same folder, which contain parameters about the location of file system and its name (core-site.xml), map-reduce job tracker (mapred-site.xml.template), Hadoop file system replication information (hdfs-site.xml) and YARN services connection information (yarn-site.xml).
In core-site.xml, add the following properties between <configuration/> tag:
<property> <name>hadoop.tmp.dir</name> <value>/hdfs/tmp</value> </property> <property> <name>fs.default.name</name> <value>hdfs://node1:54310</value> </property>
This shows where the Hadoop file system operation directory resides and how to access it.
In mapred-site.xml.template, add the following property between <configuration/> tag:
<property> <name>mapred.job.tracker</name> <value>node1:54311</value> </property>
Here, the host and port of the MapReduce job tracker is defined.
In hdfs-site.xml, add the following property between <configuration/> tag:
<property> <name>dfs.replication</name> <value>2</value> </property>
Normally, HDFS produces 3 replicas of each written block by default. Since we have two nodes for the time being, we should set that parameter to 2 not to get unnecessary error messages.
In yarn-site.xml, add the following properties between <configuration/> tag:
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>node1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node1:8088</value>
</property>
Now we will create the HDFS operation directory and set its user, group and permissions.
sudo mkdir -p /hdfs/tmp sudo chown hduser:hadoop /hdfs/tmp sudo chmod 750 /hdfs/tmp
Up until to this moment, the Hadoop installation was more or less the same with the first one. There are a few steps that should be accomplished before formatting the Hadoop file system.
First, we are to define which machines are slaves. These will only run DataNode and Nodemanager processes on themselves. The master machine must login them freely. We need to be sure about this.
In node1, open the slaves file.
vim /opt/hadoop-2.7.1/etc/hadoop/slaves
Add all nodes in it. The content of that file should be like this:

The very same file in node2 must be totally empty. The free login of hduser@node1 can be checked by:
su hduser ssh node1 exit ssh node2 exit
rm -rf /hdfs/tmp/*
Now, only at node1, do
hdfs namenode -format
We are ready to start the services and run our first job! The services at node1 will be run by:
start-dfs.sh start-yarn.sh
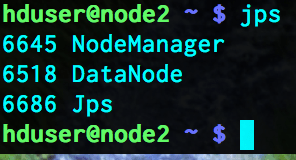
To check the running processes, run the following command in node1 and node2
jps
The processes in node1 will show

while the processes in node 2 will be
Our next topic will be about a problem that we can encounter while setting up the Hadoop cluster.

Leave a comment